Publications
Group highlights
(For a full list see below)
We have made a Norwegian, 5000+ hour dataset for weak supervision ASR (e.g. Whisper) by aligning audio from the Norwegian parliament with the official parliamentary proceedings
Per Erik Solberg, Pierre Beauguitte, Per Egil Kummervold, Freddy Wetjen
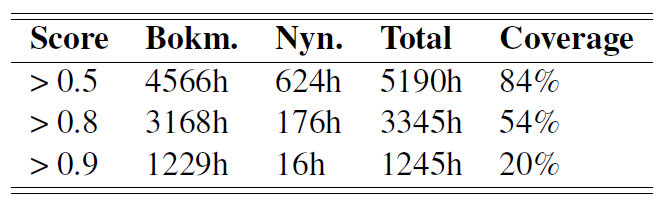
We present a study on optimizing the variability of training material for ASR when the linguistic resources are limited.
Per Erik Solberg, Pablo Ortiz, Phoebe Parsons, Torbjørn Svendsen, Giampiero Salvi
https://aclanthology.org/2023.nodalida-1.51/ (2023)
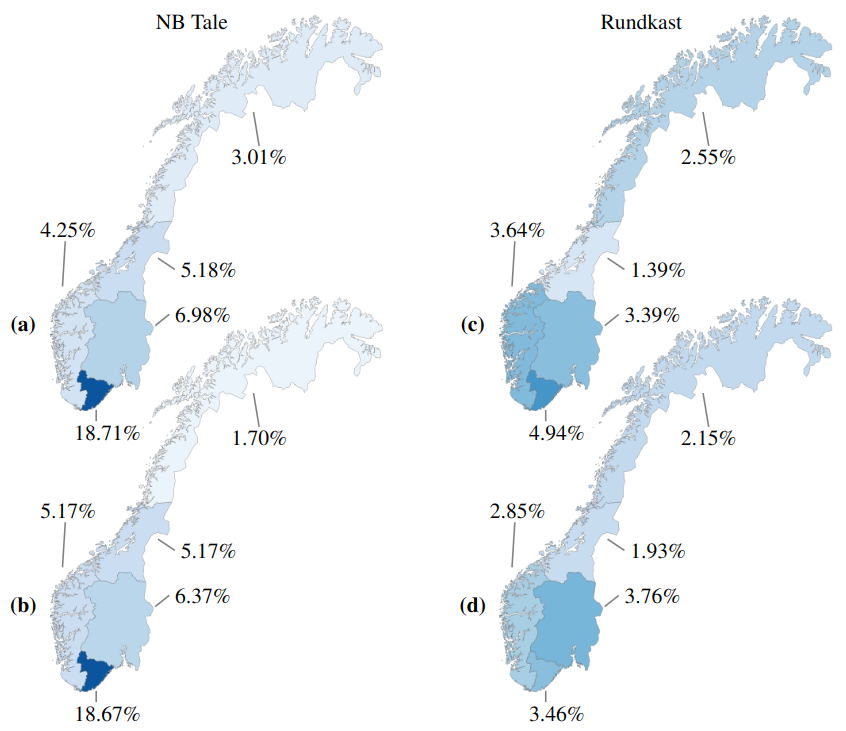
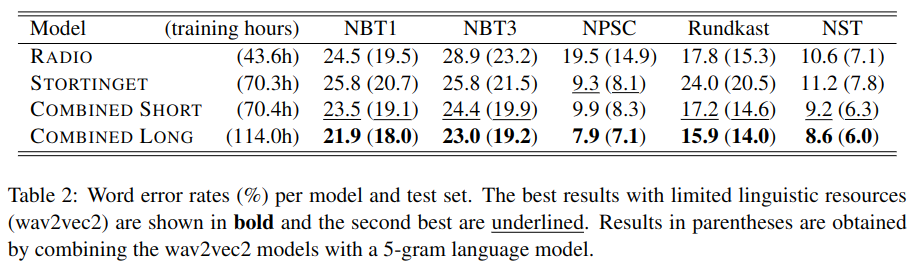
We propose an analysis of the impact of dialect on ASR results for Norwegian.
Phoebe Parsons, Knut Kvale, Torbjørn Svendsen, Giampiero Salvi
https://aclanthology.org/2023.nodalida-1.47/ (2023)
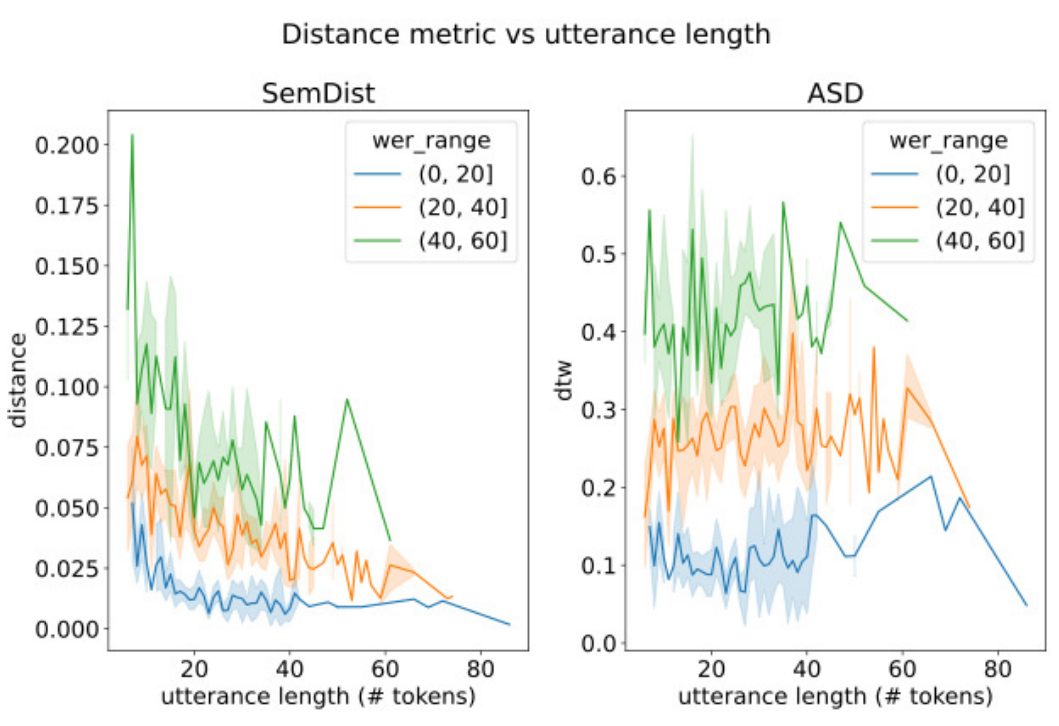
We propose a new semantically meaninful metric based on BERT and dynamic programming for ASR evaluation.
Janine Rugayan, Torbjørn Svendsen, Giampiero Salvi
10.21437/Interspeech.2022-817 (2022)
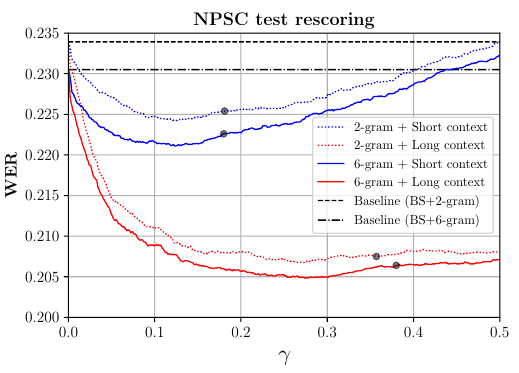
We propose new, data-efficient training tasks for BERT models that improve performance of automatic speech recognition (ASR) systems on conversational speech.
Pablo Ortiz, Simen Burud
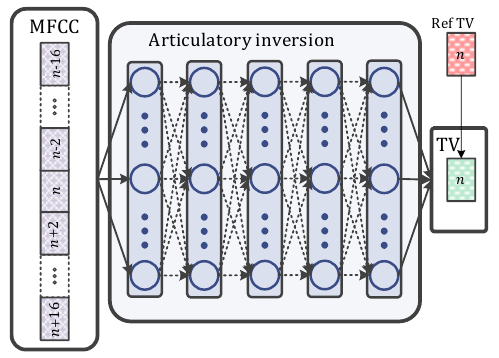
We investigate the problem of speaker independent acoustic-to-articulatory inversion (AAI) in noisy conditions within the deep neural network (DNN) framework.
Abdolreza Sabzishahrebabaki, Giampiero Salvi, Torbjørn Karl Svendsen, Sabato Marco Siniscalchi

The Norwegian Parliamentary Speech Corpus (NPSC) is the first, publicly available dataset containing unscripted, Norwegian speech designed for training of automatic speech recognition (ASR) systems. The NPSC-trained system performed significantly better, with a 22.9% relative improvement in word error rate (WER) and a “democratizing” effect in terms of dialects.
Per Erik Solberg, Pablo Ortiz
Full List
An Analysis of Goodness of Pronunciation for Child Speech
Xinwei Cao, Zijian Fan, Torbjørn Svendsen, Giampiero Salvi
https://www.interspeech2023.org/
Perceptual and Task-Oriented Assessment of a Semantic Metric for ASR Evaluation
Janine Rugayan, Giampiero Salvi, Torbjørn Svendsen
https://www.interspeech2023.org/
A Large Norwegian Dataset for Weak Supervision ASR
Per Erik Solberg, Pierre Beauguitte, Per Egil Kummervold, Freddy Wetjen
https://www.researchgate.net/publication/370766648_A_Large_Norwegian_Dataset_for_Weak_Supervision_ASR (2023)
Improving Generalization of Norwegian ASR with Limited Linguistic Resources
Per Erik Solberg, Pablo Ortiz, Phoebe Parsons, Torbjørn Svendsen, Giampiero Salvi
https://aclanthology.org/2023.nodalida-1.51/ (2023)
A character-based analysis of impacts of dialects on end-to-end Norwegian ASR
Phoebe Parsons, Knut Kvale, Torbjørn Svendsen, Giampiero Salvi
https://aclanthology.org/2023.nodalida-1.47/ (2023)
Semantically Meaningful Metrics for Norwegian ASR Systems
Janine Rugayan, Torbjørn Svendsen, Giampiero Salvi
10.21437/Interspeech.2022-817 (2022)
BERT Attends the Conversation: Improving Low-Resource Conversational ASR
Pablo Ortiz, Simen Burud
arXiv:2110.02267 (2021)
Acoustic-to-Articulatory Mapping with Joint Optimization of Deep Speech Enhancement and Articulatory Inversion Models
Abdolreza Sabzishahrebabaki, Giampiero Salvi, Torbjørn Karl Svendsen, Sabato Marco Siniscalchi
10.1109/TASLP.2021.3133218
The Norwegian Parliamentary Speech Corpus
Per Erik Solberg, Pablo Ortiz
Proceedings of LREC2022