Introduction
(More details in Research)
Objectives
SCRIBE’s primary objective is to develop a Norwegian speech-to-text transcription system for multi-party conversations in realistic recording conditions.
In order to attain the project goal, research and technology development beyond the state-of-the-art is needed within several key areas. These include language universal issues, as well as issues specifically related to the Norwegian language.
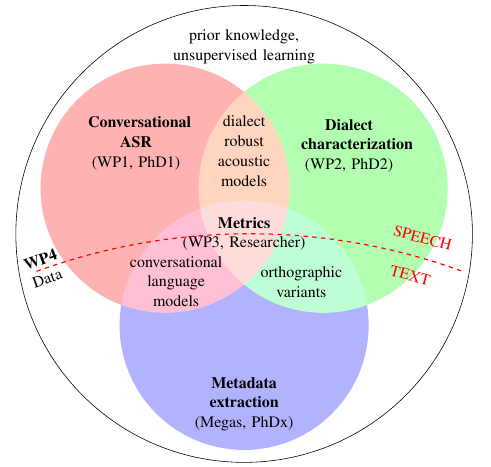
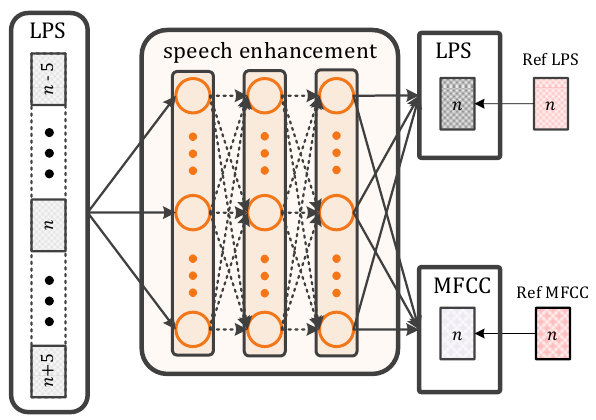
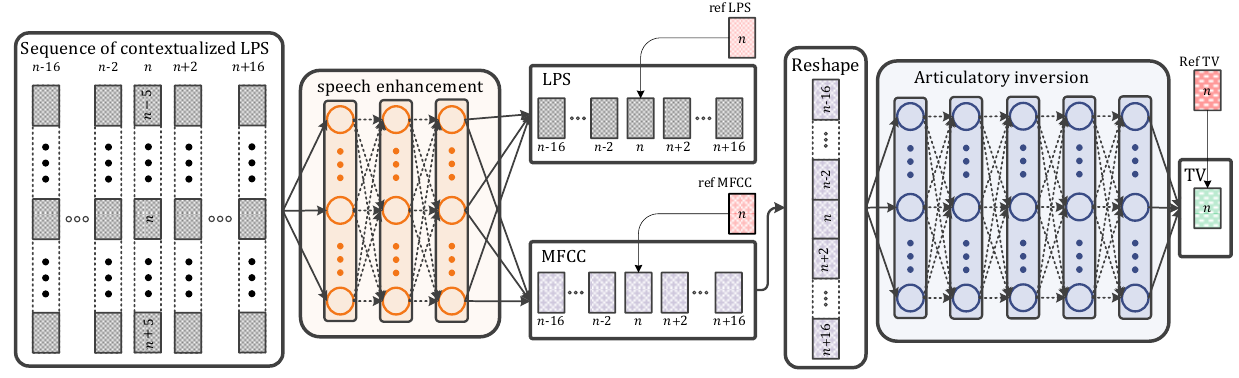
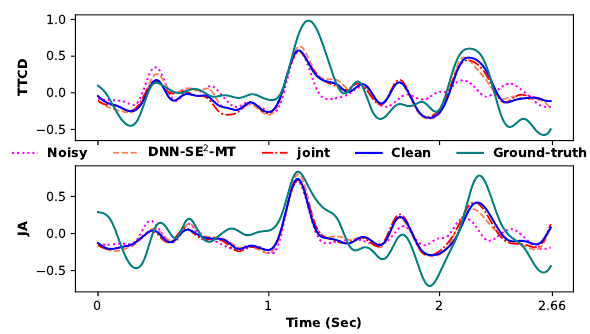
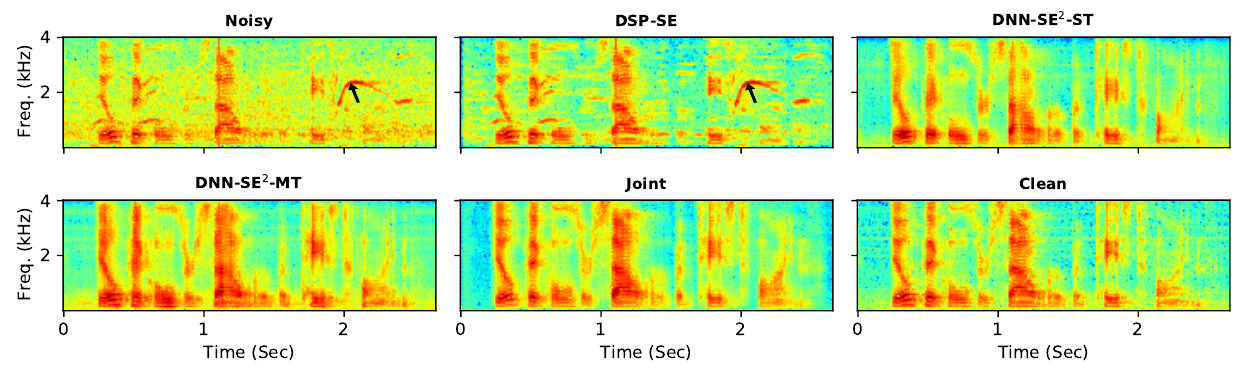
Secondary Objectives
- We will develop models that are robust to disfluencies that are typical in spontaneous conversational speech, that can cope with turn taking and take advantage of the context in the dialog.
- The models will also support the use of spoken dialects and different orthographies (Bokmål, Nynorsk, or dialect specific).
- We will define evaluation metrics that predict the quality of the transcription based on semantics rather than merely word error rate.
- Finally, we will contribute to the theoretical and methodological development of machine learning with sparse data.
We are grateful for funding from The Research Council of Norway within the IKTPLUSS initiative.






News
22. May 2026Tollef Jørgensen defended his thesis On Metadata Generation and Summarization for Conversational Text!
18. Mar. 2026Phoebe Parsons defended her thesis On Dialects and Speech Technology!
26. Jun. 2025Two papers from the SCRIBE team accepted at TSD 2025! See you in Germany!
24. Jun. 2025Two papers from the SCRIBE team accepted at IEEE MLSP 2025! See you in Turkey!
19. May. 2025One paper from the SCRIBE team accepted at Interspeech 2025! See you in the Netherlands!
5. Feb. 2025Tollef Jørgensen organized a workshop at IDI/NTNU on using Large Language Models, some code here.
31. Jan. 2025Tollef Jørgensen was interviewed by NRK about the DeepSeek Hype, listen here
10. Dec. 2024Both SCRIBE submissions to NoDaLiDa were accepted! See you in Tallin, Estonia!
29. Nov. 2024SCRIBE members were invite to present at CuttingEdgeAI - Talking to Machines in Oslo, Norway!
... see all News
Industrial Partners